Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
by Andrei Frumusanu on March 10, 2020 8:30 AM EST- Posted in
- Servers
- CPUs
- Cloud Computing
- Amazon
- AWS
- Neoverse N1
- Graviton2
Cost Analysis - An x86 Massacre
The Graviton2 showcased that it can keep up extremely well in terms of performance and throughput, even beating the competition in a lot of the tests. However sometimes you don’t care too much about performance, and you just want to get some workload completed in the cheapest way possible, at which point value comes into play.
Amazon does allude to that, stating that the new chip is able to achieve 40% better performance per dollar than its competition. As covered in the introduction, for the 64-vCPU count 16xlarge instances the m6g (Graviton2), m5a (EPYC1), and m5n (Xeon Cascade Lake) are priced at an hourly cost of $2.464, $2.752 and $3.808 respectively.
Translating the time to completion of our various SPEC tests to hours and multiplying by the hourly cost, we end up with a cost per fixed workload metric:

An aggregate of all workloads summed up together, which should hopefully end up in a representative figure for a wide variety of real-world use-cases, we do end up seeing the Graviton2 coming in 40% cheaper than the competing platforms, an outstanding figure.
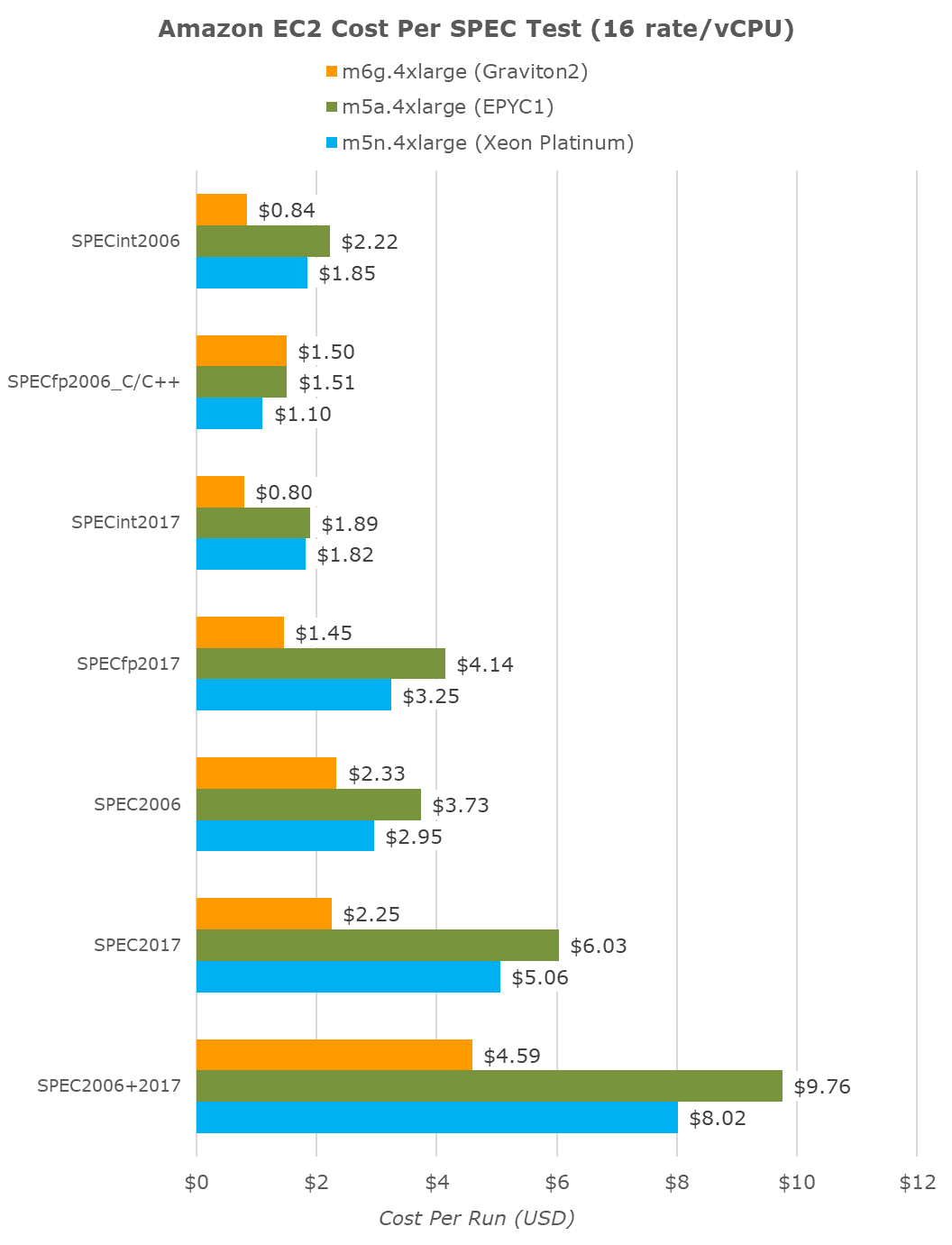
If we were to compare the same fixed workload at smaller instance counts, because of Graviton2’s better per-thread performance, we’re seeing even better results on 4xlarge (16 vCPUs) instances. Here the Amazon chip showcases 43% better value than the Xeon chip, and beats the AMD instances by being 53% cheaper.
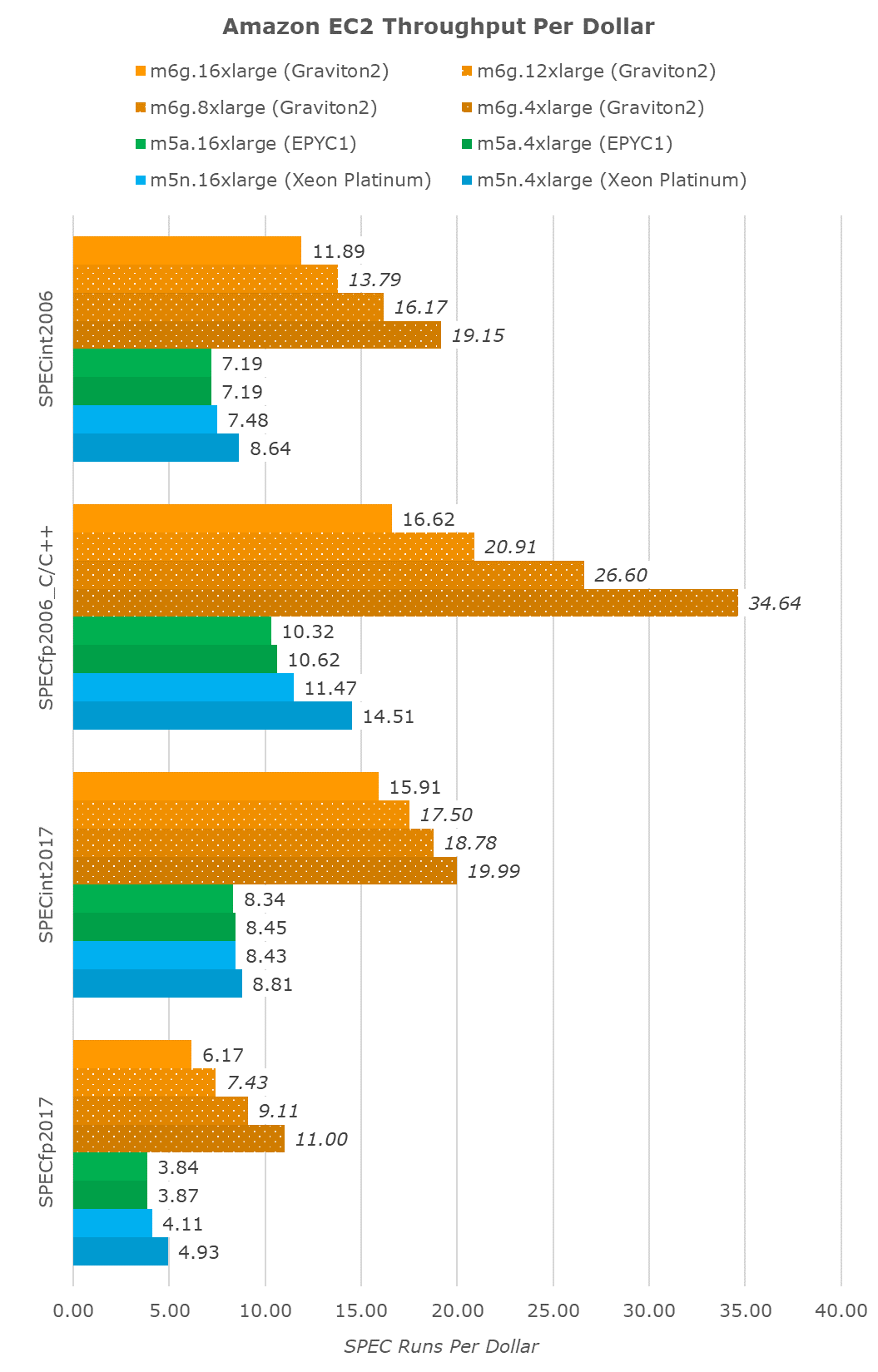
If we were to transform the results into a fixed throughput per dollar metric, we again see the Graviton2 far ahead. The unit here is SPEC runs per dollar.
The lower the vCPU instance size, the better value the Graviton2 seemingly becomes, as its performance with increased vCPUs scales sublinearly, but the cost of bigger vCPU instances scales linearly, an effect that’s almost not present at all in the AMD system, and only marginally present in the Xeon instances.
Again, the Graviton2’s scaling here might differ in production instances, but given that you can’t just chop off half the chip (or have access to only one of two sockets, in Intel’s case here) and that Amazon seemingly isn’t doing any static partitioning of the chip’s shared resources, I do think it’s more likely than not that such performance and value figures will be encountered in the real-world.
Even ignoring the lower vCPU instances, Amazon was able to deliver on its promise of 40% better performance per dollar, and it’s a massive shakeup for the AWS and EC2 ecosystem.








96 Comments
View All Comments
anonomouse - Tuesday, March 10, 2020 - link
Will there be more articles on this, covering other workloads than SPEC? You see lots of academic and industry papers talking about how real cloud/hyperscaler/server workloads have deep software stacks with large instruction-side footprints and static branch footprints, whereas SPEC is really... not that. Those workloads tend to have lower IPC on all platforms, and it would be interesting to see how Graviton2 performs on those from the instruction-supply side of things (1 core) as well as how I-side bandwidth scales horizontally with thread counts given the coherent I-Cache.Andrei Frumusanu - Tuesday, March 10, 2020 - link
Concrete suggestions in terms of workloads too look at and can be reasonably deployed are welcome- we currently don't have a well defined test suite for such things.FunBunny2 - Tuesday, March 10, 2020 - link
"Concrete suggestions in terms of workloads"OLTP on RDBMS?? real one, of course, not MySql. :)
Andrei Frumusanu - Tuesday, March 10, 2020 - link
I mean an actual concrete example of such a structured benchmark, me going around doing random DB operations just opens up more criticism on why we didn't use test framework XYZ.FunBunny2 - Tuesday, March 10, 2020 - link
here's one: https://hammerdb.com/ don't know, perhaps likely, that you can get the source and compile for any db/OS of interest. didn't say it was simple. :)Andrei Frumusanu - Wednesday, March 11, 2020 - link
It's just I'm hearing a lot of "we want something specific" without actually specifying anything, me doing some random workload myself that isn't validated in terms of characterisation isn't in my view any better than the well understood nature of SPEC.anonomouse - Wednesday, March 11, 2020 - link
Have you looked at the benchmarks in GCP PerfKitBenchmarker (https://github.com/GoogleCloudPlatform/PerfKitBenc... It includes benchmark versions of various popular benchmarks including variants of ycsb on different databases, oltp, cloudsuite, hadoop, and a bunch of wrapper infrastructure around running the tests on cloud providers.anonomouse - Wednesday, March 11, 2020 - link
Okay so maybe the comment system doesn't have well with links:https://github.com/GoogleCloudPlatform/PerfKitBenc...
http://googlecloudplatform.github.io/PerfKitBenchm...
yeeeeman - Tuesday, March 10, 2020 - link
Ok, now imagine this chip with apple custom cores. Even Zen wouldn't stand a chance.HStewart - Tuesday, March 10, 2020 - link
You can't truly say that. Keep in mind both Apple and Amazon are aim at there own custom environments - things are like different in real world.